Class Tree with Implemented Methods¶
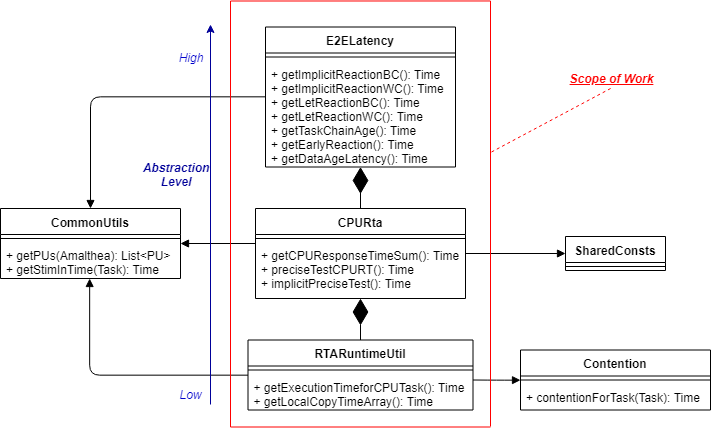
The above UML class diagram describes the project’s implementation in a hierarchical way.
Key Classes¶
E2ELatency¶
The top layer takes care of the end-to-end latency calculation of the observed task-chain based on the analyzed response time from the CPURta class. It includes calculating E2E latency values according to the concepts stated in the theory part (e.g., Reaction, Age).
Task Chain Reaction (Implicit Communication Paradigm)¶
public Time getTCReactionBC(final EventChain ec, final ComParadigm paradigm, final CPURta cpurta)
This method derives the given event-chain’s best-case end-to-end latency based on the reaction concept for the direct and implicit communication paradigms.
public Time getTCReactionWC(final EventChain ec, final ComParadigm paradigm, final CPURta cpurta)
This method derives the given event-chain’s worst-case end-to-end latency value based on the reaction concept for the direct and implicit communication paradigms.
For the details, see Task Chain Reaction (Implicit Communication Paradigm) and features-e2elatency.
Task Chain Reaction (Logical Execution Time Communication Paradigm)¶
public Time getLetReactionBC(final EventChain ec, final CPURta cpurta)
This method derives the given event-chain’s best-case end-to-end latency value based on the reaction concept for LET communication.
public Time getLetReactionWC(final EventChain ec, final CPURta cpurta)
This method derives the given event-chain’s worst-case end-to-end latency based on the reaction concept for LET communication.
For the details, see Task Chain Reaction (Logical Execution Time Communication Paradigm) and features-e2elatency.
Task Chain Age¶
public Time getTaskChainAge(final EventChain ec, final TimeType executionCase, final ComParadigm paradigm, final CPURta cpurta)
This method derives the given event-chain latency based on the age concept.
By changing TimeType executionCase parameter, the latency in the best-case or the worst-case can be derived.
For the details, see Task Chain Age and features-e2elatency.
Task Chain Early Reaction¶
public Time getEarlyReaction(final EventChain ec, final TimeType executionCase, final ComParadigm paradigm, final CPURta cpurta)
This is a method to be pre-executed for getting the reaction-update latency values.
The best-case and worst-case early-reaction latency values should be derived first and then the reaction update latency can be calculated.
By changing TimeType executionCase parameter, the latency in the best-case or the worst-case can be derived.
For the details, see early-reaction and features-e2elatency.
Data Age¶
public Time getDataAge(final Label label, final EventChain ec, final TimeType executionCase, final ComParadigm paradigm, final CPURta cpurta)
This method derives the given label’s age latency.
If the passed event-chain does not contain the observed label, null is returned.
By changing TimeType executionCase parameter, the latency in the best-case or the worst-case can be derived.
For the details, see Data Age and features-e2elatency.
CPURta¶
The middle layer takes care of analyzing task response times. It is responsible for calculating response times according to the communication paradigm (Direct or Implicit communication paradigm).
Response Time Sum¶
public Time getCPUResponseTimeSum(final TimeType executionCase)
This method derives the sum of all the tasks’ response times according to the given mapping model (which is described as an integer array). The method can be used as a metric to assess a mapping model.
Response Time (Direct Communication Paradigm)¶
public Time preciseTestCPURT(final Task task, final List<Task> taskList, final TimeType executionCase, final ProcessingUnit pu)
This method derives the response time of the observed task according to the classic response time equation.
The response time can be different depending on the passed taskList which is derived from the mapping model.
Here, we are concerning response time for RMS (Rate Monotonic Scheduling).
It means that a task with the shorter period obtains a higher priority.
Before the taskList is passed to the method, it should be sorted in the order of shortest to longest and this job is done by taskSorting(List<Task> taskList) which is a private method.
Response Time (Implicit Communication Paradigm)¶
public Time implicitPreciseTest(final Task task, final List<Task> taskList, final TimeType executionCase, final ProcessingUnit pu, final CPURta cpurta)
This method derives the response time of the task parameter according to the classic response time equation but in the implicit communication paradigm.
In the implicit communication paradigm which is introduced by AUTOSAR. A task copies in its required data (labels) to its local memory at the beginning of its execution, computes in the local memory and finally copies out the result to the shared memory.
Due to these copy-in & copy-out costs, extra time must be added to the task’s execution time which is done by getLocalCopyTimeArray (for the details, see Local Copy Cost for the Implicit Communication Paradigm) which is a method from the RTARuntimeUtil class.
As a result, the task’s execution time gets longer while its period should stays the same.
Once the local-copy cost is taken into account, the remaining process is the same as Response Time (Direct Communication Paradigm)
For the details, see response-time and features-rta.
RTARuntimeUtil¶
The bottom layer takes care of task and runnable execution time. It is responsible for calculating memory access costs, execution ticks or execution needs, and computation time.
CPU Task Execution Time¶
public Time getExecutionTimeforCPUTask(final Task task, final ProcessingUnit pu, final TimeType executionCase, final CPURta cpurta)
This method derives the execution time of the task parameter under one of the following cases:
- The CPU task triggers a GPU task in the synchronous offloading mode
- The CPU task triggers a GPU task in the asynchronous offloading mode
(For the details, see Synchronous & Asynchronous Mechanism.)
- The GPU task is mapped to a CPU
According to the WATERS challenge, a triggering task (PRE_..._POST) can be ignored if the triggered task is mapped to a CPU.
For example, the following Figure shows the SFM task which is mapped to the GPU by default.
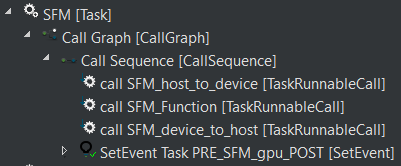
If the task is mapped to CPU, the offloading runnables (SFM_host_to_device, SFM_device_to_host) which are in charge of offloading workload to GPU and copying back to CPU are obsolete.
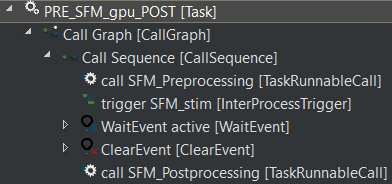
Instead, the labels from runnables before (Pre-processing) & after (Post-processing) the InterProcessTrigger are considered.
For the runnable, Pre-processing, read labels and read latency values are taken into account.
For the runnable, Post-processing, write labels and write latency values are taken into account.
This job is done by the private method getExecutionTimeForGPUTaskOnCPU().
- Task with only Ticks (pure computation)
When a CPU task without any triggering behavior is passed, only the execution time that corresponds to the task’s ticks is considered.
Code Reference for getExecutionTimeforCPUTask
Except for the very last case (Task with only Ticks), the task execution time calculation always includes memory accessing costs.
Calculating memory accessing costs is taken care of by methods such as getExecutionTimeForRTARunnable, getRunnableMemoryAccessTime which are defined as private.
Code Reference for getExecutionTimeForRTARunnable Code Reference for getRunnableMemoryAccessTime
For the details, see Memory Access Cost.
Local Copy Cost for the Implicit Communication Paradigm¶
public Time[] getLocalCopyTimeArray(final Task task, final ProcessingUnit pu, final TimeType executionCase, final CPURta cpurta)
As it is introduced in Response Time (Implicit Communication Paradigm), label copy-in and copy-out costs should be calculated and added to the total execution time of the target task.
The following equation from End-To-End Latency Characterization of Implicit and LET Communication Models is used to calculate these costs.

Where  denotes the execution time of the runnable
denotes the execution time of the runnable tau_0,  represents the inputs (read labels) of the considered task and
represents the inputs (read labels) of the considered task and  denotes the time it takes to access a shared label
denotes the time it takes to access a shared label  from memory
from memory  .
.

Where  denotes the execution time of the runnable
denotes the execution time of the runnable tau_last,  represents the outputs (write labels) of the considered task and denotes the time it takes to access a shared label from memory .
represents the outputs (write labels) of the considered task and denotes the time it takes to access a shared label from memory .
For the copy-in cost, only read labels should be taken into account. The copy-in cost time is stored on index 0 of the return array. This will later be considered as the execution time of the copy-in runnable which is added to the beginning of the task execution.
For the copy-in cost, only write labels should be taken into account. The copy-in cost time is stored on index 1 of the return array. This will later be considered as the execution time of the copy-out runnable which is added to the end of the task execution.
Supplementary Classes (Out of scope)¶
CommonUtils¶
public static List<ProcessingUnit> getPUs(final Amalthea amalthea)
This method derives a list of processing units of the target Amalthea model.
It places CPU type processing units in the front and that of GPU type in the tail (end) of the list.
public static Time getStimInTime(final Task t)
This method returns the periodic recurrence time of the target task. If the passed task is not a periodic task (e.g., GPU task), the recurrence time of a task which is periodic and triggers the target task is returned. Otherwise time 0 is returned.
Contention¶
public Time contentionForTask(final Task task)
This method derives a memory contention time which represents the delay when more than one CPU core and/or the GPU is accessing memory at the same time.
For the details, see Memory Contention Model.